Agentic AI is the buzzword of the season. And for all the right reasons. But 2 serious drawbacks of Agentic AI are high costs and slow speed due to the usage of reasoning models for crafting a plan for agent invocation (and tool usage) and multi-step LLM calls for finally arriving at the end goal. Model Distillation is a very well placed offering made GA by the hard working team at Amazon just few days ago.
What is Model Distillation, eh?
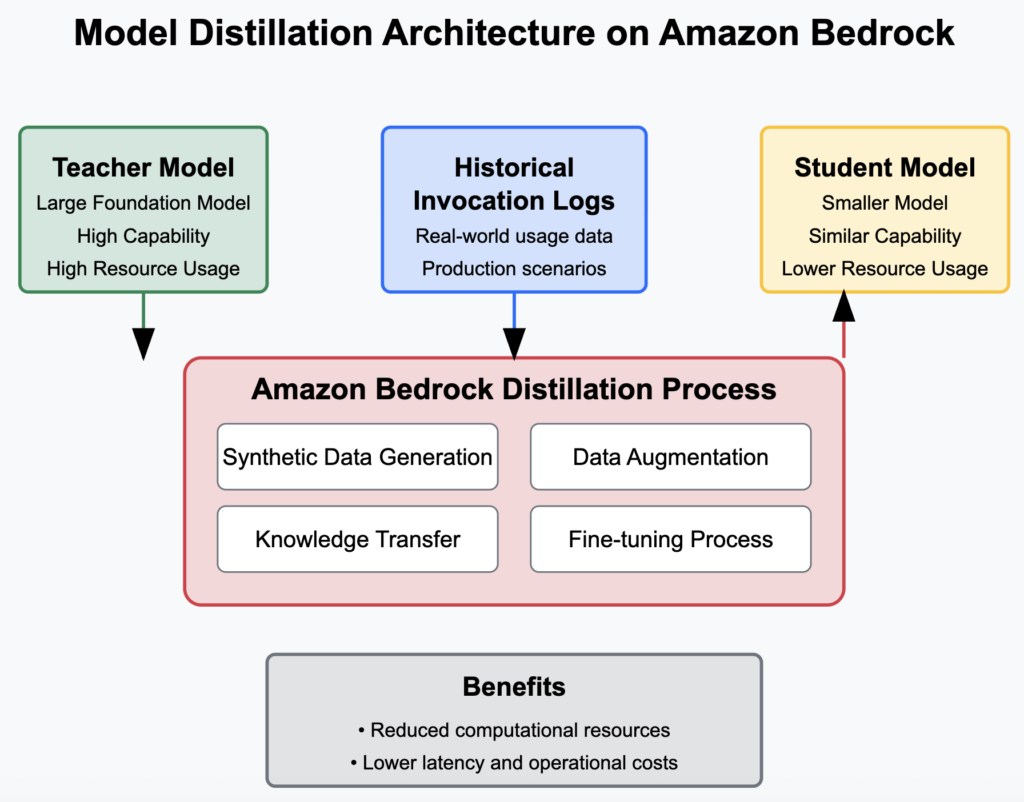
Model distillation involves transferring knowledge from a larger, more capable “teacher” model to a smaller “student” model. This process allows the student model to perform comparably to the teacher model for specific tasks, but with lower latency, and lesser costs. Let’s take an analogy to understand this better. Consider a multi-talented College Professor who is an expert at taking lectures on Physics, AI, Biology and Literature. (That’s akin to our top-of-the-end LLMs). Enter our Student with say a reduced capacity for performance compared to the Professor. He only attends the Literature lectures and spends a lot of time with the Professor on ramping up his Literature competency. This is how we are able to do task-specific or domain-specific fine-tuning using a Teacher-Student pair of LLMs. Amazon Bedrock simplifies this otherwise tedious process, utilising synthetic data generation and advanced data augmentation techniques to fine-tune the student model effectively .
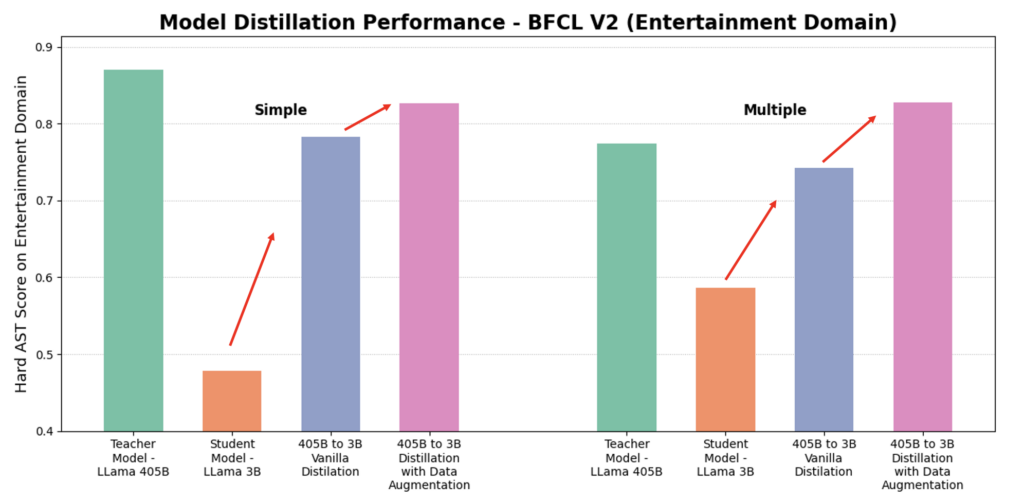
Check out the performance comparison from their blog below.
Leveraging Historical Invocation Logs
Now if that wasn’t cool enough for you there is another super-neat feature. The ability to utilise historical invocation logs. What’s that? Organisations can enable logging of model interactions over time in Bedrock, capturing real usage data of their actual applications. This data can then be used to fine-tune smaller models, ensuring they are optimised for actual production scenarios without the need for manual dataset creation. This approach not only streamlines the fine-tuning process but also reduces costs associated with data generation. Win-Win!
Strategic Value
Hats off to the Product team at AWS for focussing on the right features to build out. From a business perspective, this development enhances customer retention and platform stickiness. Also true to their motto, this is a “customer-first” feature that eventually helps the customers reduce costs on LLM usage. (Do note that there are additional costs for hosting a custom model on Bedrock though. But that would get offset by your high-volume usage of a cheaper model.)
Looking ahead, I wouldn’t be surprised if Amazon Web Services (AWS) will introduce features that proactively identify optimisation opportunities. For instance, I would be super happy to receive notifications like this “Hey, we noticed you are using Claude Sonnet 3.7. If you were to distill this into model x, your monthly savings would be $300 PM and your requests would be faster by 35%. Hit this button to do the auto-distillation.”
Amazing time to be working in the software engineering space!
Image Credits: Sora, Cladius & Claude